Memory Matters in PostgreSQL : Configuring max_connections and work_mem Effectively
Hello everyone! In this blog post, I’ll discuss the relationship between the work_mem (and maintenance_work_mem) and max_connections parameters in PostgreSQL. These two settings play a key role in determining memory usage and overall performance, making them central to any tuning efforts aimed at future performance goals. While PostgreSQL includes other memory-related parameters, this post will focus specifically on how work_mem and max_connections interact and impact system performance.
The outline of this blogpost as follows;
- The definition of work_mem and max_connections
- The relationship between two GUC settings
- Configuring work_mem and max_connections to provide more reliable PostgreSQL
- Benchmarks with different settings.
Definition of Parameters
The definitions are stated at official PostgreSQL documentation page. Basically work_mem sets the base maximum amount of memory to be used by a query operation (such as a sort or hash table) before writing to temporary disk files. If this value is specified without units, it is taken as kilobytes.
On the other hands, max_connections parameter determines the maximum number of concurrent connections to the database server. The default is typically 100 connections, but might be less if your kernel settings will not support it (as determined during initdb). This parameter can only be set at server start. PostgreSQL sizes certain resources based directly on the value of max_connections. Increasing its value leads to higher allocation of those resources, including shared memory.
I’m not going to discuss how to change this parameters but shortly we can visit our PostgreSQL configuration file or execute the following commands on database. Keep in mind that changing max_connection parameter requires PostgreSQL service to be restarted
ALTER SYSTEM SET work_mem TO '2MB';
ALTER SYSTEM SET max_connections TO 500;The Relationship Between Two Parameters
When it comes to work_mem parameter, it can affect the query performance and I/O performance itself. Because if it is not big enough to store temporary information including sorting and grouping it will do it on disk.
When PostgreSQL prefers disk to sort or group items it causes performance problem or it may have an impact on performance. In other words, query performance can be affected by work_mem because of unwanted disk sorting operation On the other hand, since work_mem is allocated per operation within each connection, the total potential memory consumption scales with the number of active connections. In practice, this means:
Total Memory Usage = max_connections x work_mem (approximate, as the actual memory depends on query complexity and concurrency).
For example, if work_mem is set to 16 MB and max_connections to 100, the database could potentially consume up to 1.6 GB of memory for active operations alone.
To decide a more sustainable and efficient value for max connections setting we can contemplate the following issues.
- Memory in Server (MB): Total available memory in the instance(server).
- Work Mem configuration(MB): Memory allocated for each query operation. We assume it 1MB at least for each PostgreSQL instance.
- Shared Buffer Configuration(MB): Shared buffers are set to 25% of total RAM, which is a typical PostgreSQL configuration.
- Base Overhead(MB): a constant value based on PostgreSQL’s internal structures and the number of connections.
- Buffer Percentage(Integer): This sets aside 15% of the total RAM for the operating system and other non-PostgreSQL processes.
- Maintenance Buffer(Integer): Sets aside 10% of total RAM for maintenance operations, such as vacuuming and indexing.
Configuring Max Connections and Work Mem Parameters in PostgreSQL
Properly configuring these parameters depends heavily on specific requirements and workloads. I’ve written a script to automate this process you can find the script at the end of this section. This script offers a formulaic approach to gauge memory limitations and potential bottlenecks. It calculates an estimation for safe and sustainable values, helping to avoid configurations that might exhaust available memory under load.
Explanation with Emphasis on Formula and Evaluation Process
The script provides a methodical way to evaluate memory allocations, guiding users to set max_connections and work_mem in a balanced manner. It factors in system overhead and specific PostgreSQL requirements to estimate safe memory usage based on available RAM. Here’s how the script’s calculations can guide configuration:
- Use Case and Workload Dependency
The optimal values for max_connections and work_mem are closely tied to workload characteristics. High-concurrency OLTP systems may require a higher max_connections with lower work_mem settings, while OLAP systems may benefit from fewer connections but more work_mem per connection.
This script provides baseline recommendations that users can adjust based on their workload requirements.
- Formula for Memory Estimation
The script calculates the total memory overhead for the current configuration (CURRENT_MEMORY_OVERHEAD_TOTAL). This value represents the cumulative memory PostgreSQL would consume at peak connection usage.
By comparing this total with the available memory (AVAILABLE_RAM_MB), the script evaluates whether the current configuration fits within system limits or requires adjustments.
The suggested configurations for max_connections and work_mem (Options 1 and 2) provide concrete limits based on system resources, ensuring the system does not exceed safe memory usage.
- Guidance on Memory Allocation for PostgreSQL
The script uses a formula-based approach to determine memory allocations, factoring in OS, shared buffers, and maintenance memory requirements. It calculates feasible configurations for both max_connections (with a fixed work_mem) and work_mem (with a fixed max_connections), offering flexibility depending on which parameter the user prioritizes.
By adjusting max_connections and work_mem based on this formula, users can achieve an optimal configuration that aligns with system capacity and workload demands.
This approach is a starting point for database administrators to balance memory use effectively. Testing these suggested values in a live environment and monitoring PostgreSQL’s performance is crucial for further tuning based on actual workload behavior.
#!/bin/bash
# Constants (assuming RAM and configs are provided before calculation)
TOTAL_RAM_MB=8000
CURRENT_CONNECTION_LIMIT=1000
CURRENT_WORK_MEM_MB=16
BASE_OVERHEAD_MB=8
HASH_MEM_MULTIPLIER=2
OS_MEMORY_USAGE_PERCENTAGE=25
MAINTENANCE_OS_MEMORY_USAGE_PERCENTAGE=15
# Calculate memory allocations based on total RAM and usage percentages
BUFFER_MB=$(( TOTAL_RAM_MB * OS_MEMORY_USAGE_PERCENTAGE / 100 ))
SHARED_BUFFERS_MB=$(( TOTAL_RAM_MB / 4 ))
MAINTENANCE_BUFFER_MB=$(( TOTAL_RAM_MB * MAINTENANCE_OS_MEMORY_USAGE_PERCENTAGE / 100 ))
AVAILABLE_RAM_MB=$(( TOTAL_RAM_MB - BUFFER_MB - SHARED_BUFFERS_MB - MAINTENANCE_BUFFER_MB ))
# Display current configuration
echo "Current work_mem Configuration: ${CURRENT_WORK_MEM_MB} MB"
echo "Current max_connections Configuration: ${CURRENT_CONNECTION_LIMIT}"
# Calculate memory per connection and total memory overhead
MEMORY_PER_CONNECTION_MB=$(( (CURRENT_WORK_MEM_MB * HASH_MEM_MULTIPLIER) + BASE_OVERHEAD_MB ))
CURRENT_MEMORY_OVERHEAD_TOTAL=$(( MEMORY_PER_CONNECTION_MB * CURRENT_CONNECTION_LIMIT ))
# Check if current configurations fit within available memory
if (( AVAILABLE_RAM_MB > CURRENT_MEMORY_OVERHEAD_TOTAL )); then
echo "Current max_connections and work_mem configurations are sustainable. Assuming that available memory: $AVAILABLE_RAM_MB MB"
else
echo "PostgreSQL is not going to scale with ${CURRENT_CONNECTION_LIMIT} concurrent connections, consuming ${CURRENT_MEMORY_OVERHEAD_TOTAL} MB.Please consider tuning your max_connections and work_mem parameters."
fi
# Calculate suggested max connections based on available memory and current work_mem
SUGGESTED_MAX_CONNECTION=$(( AVAILABLE_RAM_MB / MEMORY_PER_CONNECTION_MB ))
echo "Option 1 -> The maximum value for max_connections is ${SUGGESTED_MAX_CONNECTION} assuming work_mem is ${CURRENT_WORK_MEM_MB} MB."
# Calculate suggested work_mem based on current connection limit
SUGGESTED_WORK_MEM_CURRENT=$(( AVAILABLE_RAM_MB / CURRENT_CONNECTION_LIMIT ))
echo "Option 2 -> The maximum value for work_mem is ${SUGGESTED_WORK_MEM_CURRENT} MB assuming max_connections is ${CURRENT_CONNECTION_LIMIT}."Finally, there are two constat values I can explain and rationalize.
- HASH_MEM_MULTIPLIER: the value of hash_mem_multiplier parameter in PostgreSQL
- BASE_OVERHEAD_MB: It is an estimation/assumption that a single connection may consume memory up to 8MB. It can change according to your hugepages and other kernel configurations but I tried to add more extra MBs to be in the safe side.
For example let’s assume that we run the preceding script and obtained some recommendation about our current configurations. Before executing the script we provided our current work_mem and max_connections values. Afterwards, we can expect the script provide our limitations with regards to max_connections or work_mem.
Current work_mem Configuration: 16 MB
Current max_connections Configuration: 1000
PostgreSQL is not going to scale with 1000 concurrent connections, consuming 40000 MB.Please consider tuning your max_connections and work_mem parameters.
Option 1 -> The maximum value for max_connections is 70 assuming work_mem is 16 MB.
Option 2 -> The maximum value for work_mem is 2 MB assuming max_connections is 1000If the available memory is around 8GB in the instance, max_connection is 1000 and work_mem is 16MB the script has a quite obvious warning revealing that PostgreSQL will not be able to scale 1000 concurrent connections with the current work_mem value if connections are allowed to use work_mem.
As a result it is possible to evaluate two different options. The first option simply suggest to to reduce max_connections to around 70 if work_mem has to be set 16MB.
On the other hand, if the max_connection value will be set to 1000 it’s suggested to reduce work_mem to 2MB.
To sum up, the recommendations are not the only correct values and valid for every PostgreSQL instance. The main purpose of this script and approach is to understand our limits, configurations, and resource usage in a PostgreSQL instance.
Benchmarks and Results
I have also created some benchmark tests to measure the impact of configurations. For example, I tried different combinations with different work_mem and connection settings to emphasize the memory consumption and tps changes.
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
status VARCHAR(20)
);
-- Insert random data into the orders table (1 million rows)
INSERT INTO orders (customer_id, order_date, status)
SELECT
(RANDOM() * 100000)::INT, -- Random customer IDs
CURRENT_DATE - (RANDOM() * 365)::INT, -- Random dates within the last year
CASE WHEN RANDOM() > 0.5 THEN 'completed' ELSE 'pending' END
FROM
generate_series(1, 1000000);
explain analyze (select * from orders where status='pending' order by customer_id);To measure the impact I prepared two different benchmark file one of them uses work_mem with 512kB the other one uses it with 16MB value.
SET work_mem TO '512kB';
select * from orders where status='pending' order by customer_id;
SET work_mem TO '16MB';
select * from orders where status='pending' order by customer_id;Afterwards I created a simple bash script to simulate workloads and collect results.
#!/bin/bash
truncate -s 0 raw_pgbench_results.log
low_benchmark_1(){
AVG_LATENCY=$(pgbench -f workmem_low.sql -C -c 100 -j 2 -T 120 benchmark_v2)
AVG_LATENCY_2=$(echo $AVG_LATENCY | grep 'latency average' | awk '{print $45}')
echo "-------16kB Workmem with 100 Connections-------------" >> raw_pgbench_results.log
echo "$AVG_LATENCY_2" >> raw_pgbench_results.log
}
low_benchmark_2(){
AVG_LATENCY=$(pgbench -f workmem_low.sql -C -c 150 -j 2 -T 120 benchmark_v2)
AVG_LATENCY_2=$(echo $AVG_LATENCY | grep 'latency average' | awk '{print $45}')
echo "-------16kB Workmem with 150 Connections-------------" >> raw_pgbench_results.log
echo "$AVG_LATENCY_2" >> raw_pgbench_results.log
}
high_benchmark_1(){
AVG_LATENCY=$(pgbench -f workmem_high.sql -C -c 100 -j 2 -T 120 benchmark_v2)
AVG_LATENCY_2=$(echo $AVG_LATENCY | grep 'latency average' | awk '{print $45}')
echo "-------16MB Workmem with 100 Connections-------------" >> raw_pgbench_results.log
echo "$AVG_LATENCY_2" >> raw_pgbench_results.log
}
high_benchmark_2(){
AVG_LATENCY=$(pgbench -f workmem_high.sql -C -c 150 -j 2 -T 120 benchmark_v2)
AVG_LATENCY_2=$(echo $AVG_LATENCY | grep 'latency average' | awk '{print $45}')
echo "-------16MB Workmem with 150 Connections-------------" >> raw_pgbench_results.log
echo "$AVG_LATENCY_2" >> raw_pgbench_results.log
}
for i in {1..3}
do
echo "Starting pgbench benchmark"
low_benchmark_1
sleep 120
low_benchmark_2
sleep 120
high_benchmark_1
sleep 120
high_benchmark_2
doneTo sum up the benchmark scenario and details as follow;
- Created an example table, populated with data, and defined a query which will require work_mem to do sorting.
- Created two different .sql files. One of them sets work_mem to 512kB before executing the query the other sets it to 16MB before executing.
- Create a sample benchmark bash script. The script consist of four different benchmark tests. Put simply, I tried to execute 2 different benchmark .sql files with two different connection counts.
As a result, I obtained results and tried to write down some facts according to my results.For some workloads(queries) increasing work_mem value may improve performance but this change may have an impact on resource usage. The following figures show that the memory usage had increased while latency decreased.
Secondly, increasing concurrent connections to increase TPS may cause to decrease in query performance because of high memory consumption. The reason of this is that while increasing concurrent connections increases memory consumption because of work_mem. The second figure implies that when we added more 50 conccurrent connections but the latency increased. Put simply, it does not imply that increasing concurrent connections and work_mem increases query performance.
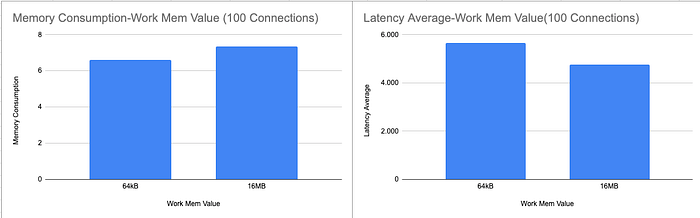
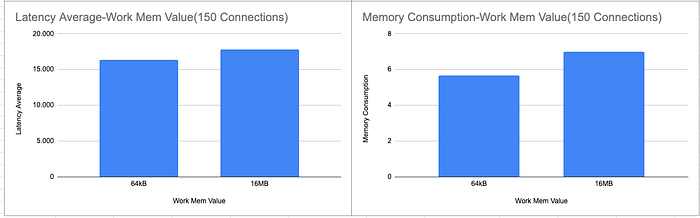
In conclusion, while adjusting work_mem and max_connections in PostgreSQL can improve query performance under certain conditions, these changes require careful consideration of memory resources and workload characteristics. The results indicate that increasing work_mem can reduce latency for specific queries, enhancing performance by allowing more in-memory processing. However, higher work_mem settings also increase overall memory usage, which can lead to resource contention, especially under high concurrency. Additionally, increasing concurrent connections to boost transactions per second (TPS) may backfire, as demonstrated by increased latency with higher connections due to memory strain. This highlights that more connections and higher work_mem do not automatically lead to better performance. Effective tuning requires balancing these parameters according to your system’s capacity and workload demands, achieving optimized performance without overextending memory limits.
Reach out to me on LinkedIn, connect on Twitter or Superpeer.May the Force guide us as we optimize our databases for greater efficiency.
Demir.
